Introduction
Quis custodiet ipsos custodes? (Juvenal). In other words: who will guard the guards themselves? If you use ntopng to monitor your network, you also need to make sure ntopng is monitored as in case of failure, ntopng will not report any alert, and the network administrator can interpret that as a sign of good health, instead of interpreting it as lack of monitoring.Recent 4.3+ versions of ntopng have the capability to monitor other ntopng instances, being them in the same local LAN or physically/geographically distributed. This capability, also referred to as infrastructure monitoring, provides live visibility of ntopng instances’ status, as well as of the network interconnecting them.
Indeed, with infrastructure monitoring, ntopng periodically performs checks against configured instances to
- Measure throughput and Round Trip Time (RTT)
- Fetch key performance and security indicators (KPI/KSI) such as the number of engaged alerts
Measures are also written as timeseries data to enable historical analysis. In addition, ntopng has the ability to trigger alerts when monitored instances become unreachable, or when their throughput or RTT falls outside expected/configured bounds.
Under the hood, checks are performed using remote instances’ REST APIs. In essence, the ntopng instance in charge of doing the infrastructure monitoring, periodically fetches remote instances’ data through their exposed REST APIs. Authentication and authorization are done using (randomly-generated) API tokens.
Infrastructure Monitoring in Practice
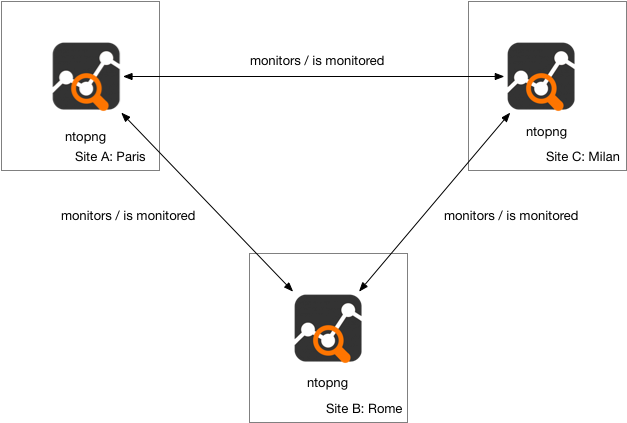
Let’s see an infrastructure monitoring example in practice. Let’s assume there are three ntopng instances running in Paris, Rome and Milan, respectively. The instance running in Rome is being used to monitor the other two instances in Paris and Milan.
To view the health and status of Paris and Milan from Rome, it suffices to go under Rome’s System -> Pollers -> Infrastructure. That pages summarises measured data from each of the two instances
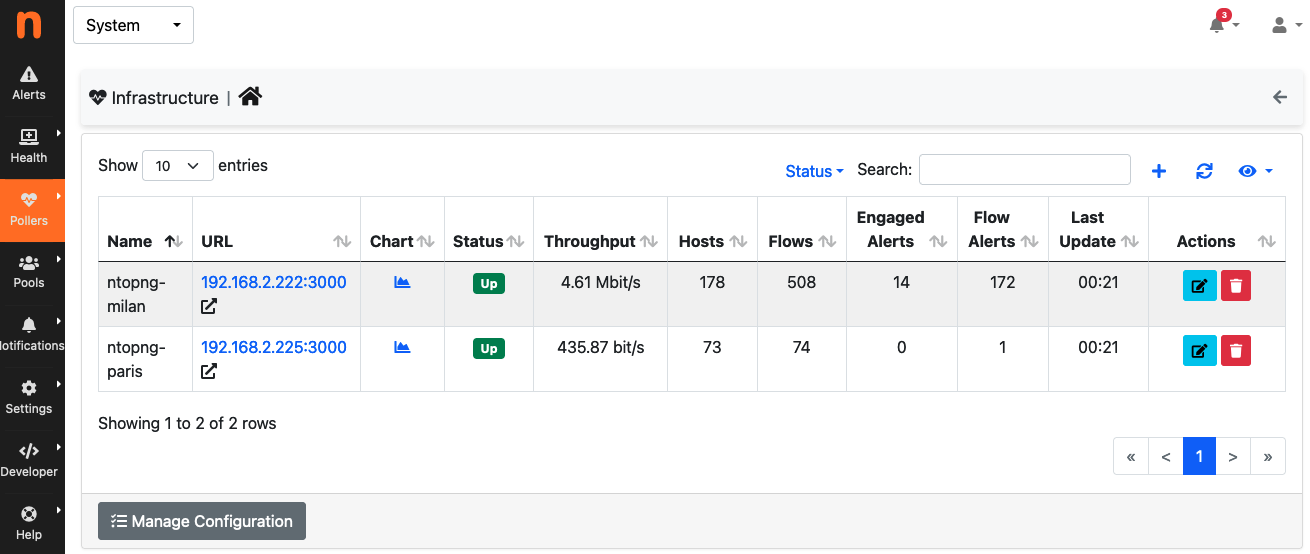
Under normal circumstances, green “UP” badges tell that everything is working as expected, with remote instances reachable, and with a throughput and RTT within the expected bounds.
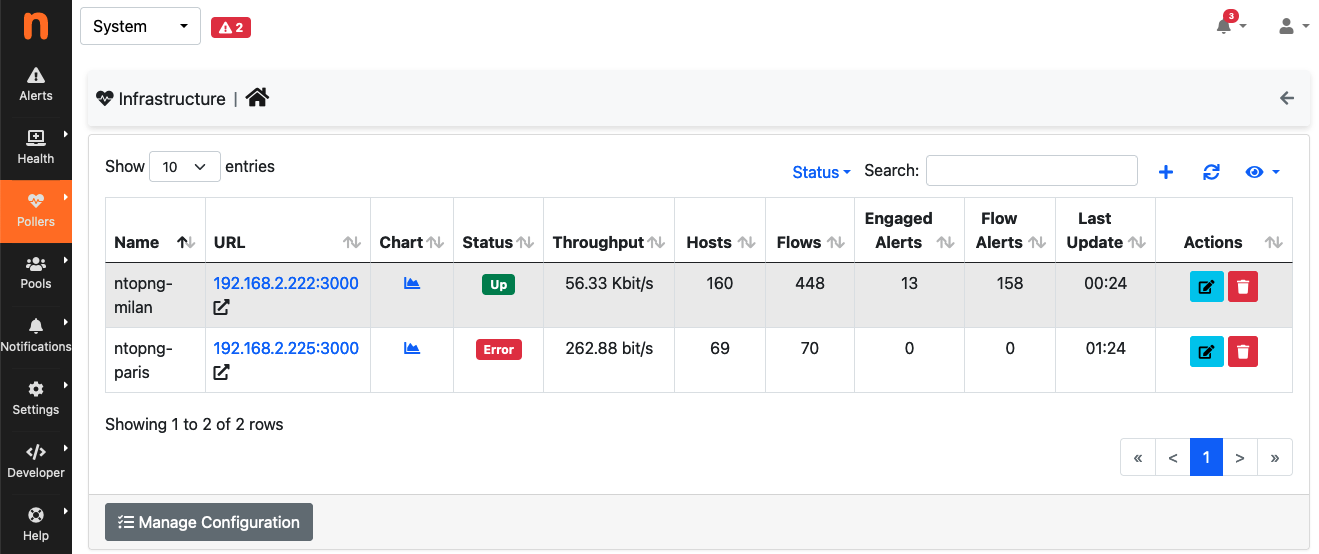
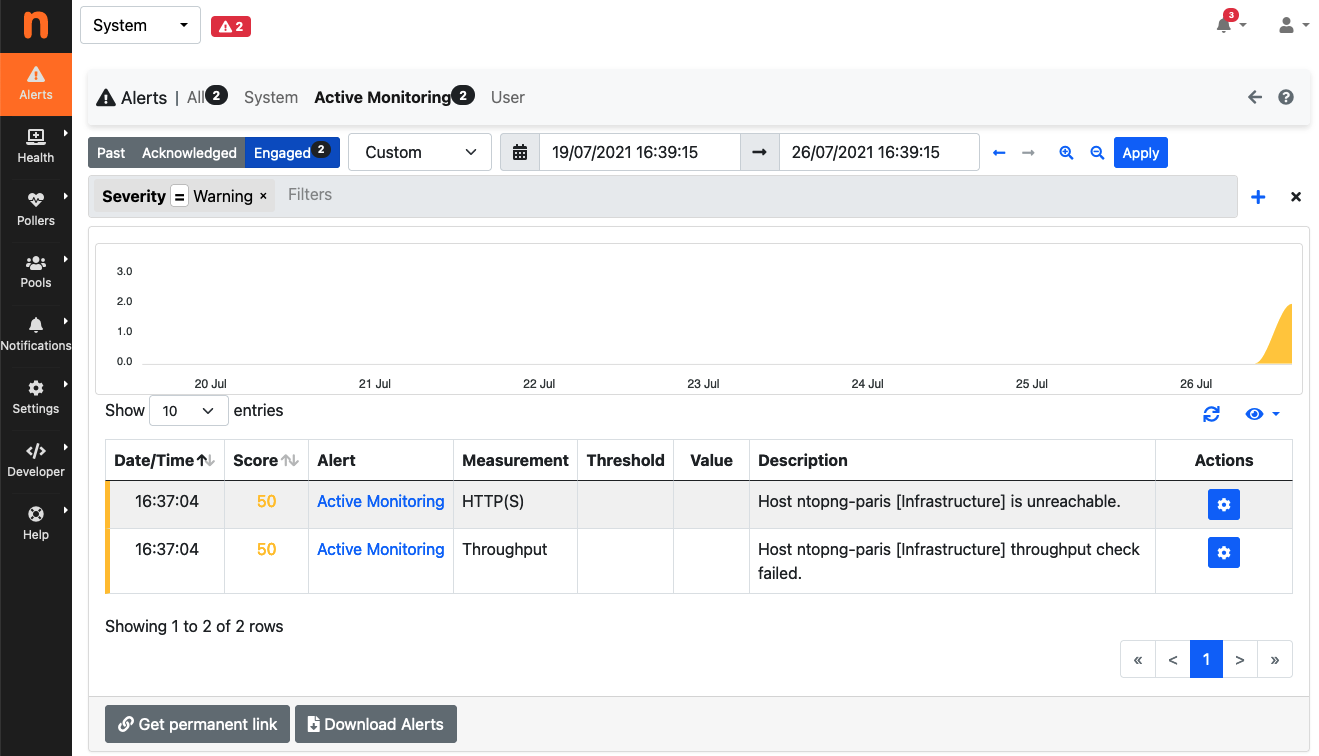
As soon as something unexpected happens, the status toggles to “ERROR” with ntopng immediately detecting the event and triggering the corresponding alerts. For the sake of example, below it is shown what happens in the event of Paris becoming unreachable
Adding Monitored Instances
In order to add monitored instances, you need to click on the plus button of the System -> Pollers -> Infrastructure page. An instance alias must be specified, along with instance URL, token, and thresholds. The image below shows the addition of Milan’s instance.
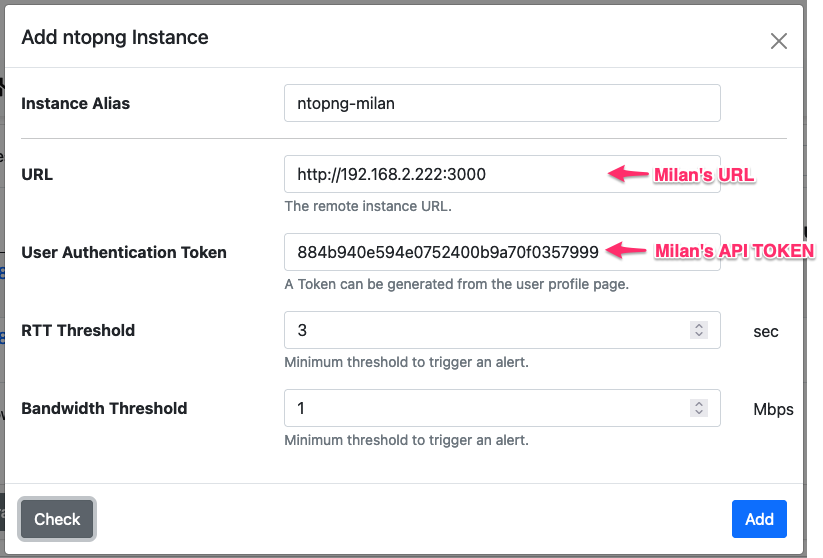
The URL is just the base ntopng URL and can be specified either with a numeric IP as well as with an symbolic name.
The token must be generated on the Milan’s instance. To generate the token, visit Milan’s page Settings -> Users. A tab “User Authentication Token” is available when editing each of the available users to generate or read the token.
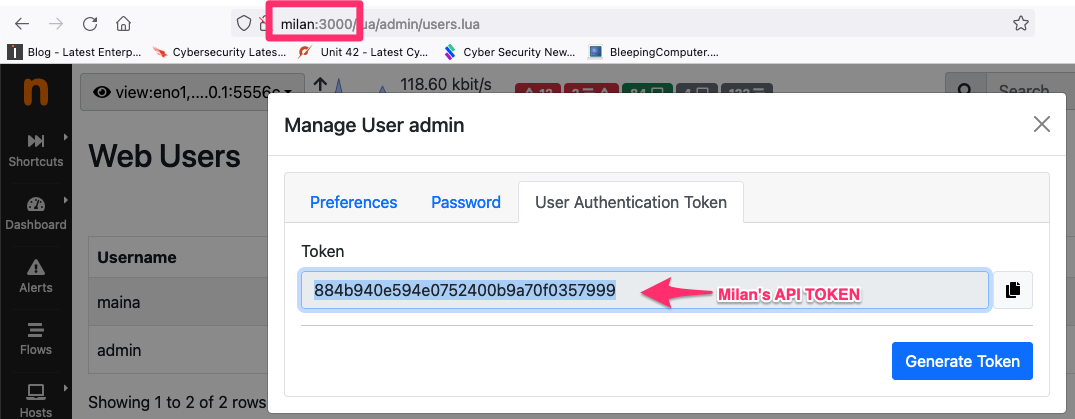
Once the token has been generated on Milan, it can be cut-and-pasted straight into Rome.
The latest two threshold allows to specify both a throughput and an RTT threshold for the instance. Every time ntopng measures fall outside these threshold, an alert is generated.
Final Remarks
In this post it has been shown how a single ntopng can be effectively used to monitor multiple sibling instances to achieve live visibility of a whole infrastructure. However the right approach is create a mesh of monitored instances so that each ntopng instance can monitor the other ones and create a robust monitoring system without a central point of failure or if you wish to positively answer the “Quis custodiet ipsos custodes?” question. This also because the measurements between ntopng instances can be different: Rome -> Paris and Paris -> Rome can have very different values in terms of throughput for instance. This is the key ingredient for reliably monitoring a ntopng-based monitoring system and indirectly monitoring the monitored network infrastructure.
Enjoy !