Motivation
Most network monitoring and security applications are based on flow processing, which is in practice the activity of grouping packets based on common attributes (e.g. source and destination IP, source and destination port, protocol, etc.) and do some analysis based on the collected information. What happens behind the scenes can be divided in a few major tasks:
- capturing raw packets
- decoding packet headers to extract flow attributes
- classify the packets based on flow attributes
- (optional) extracting also L7 protocol information.
Introducing PF_RING FT
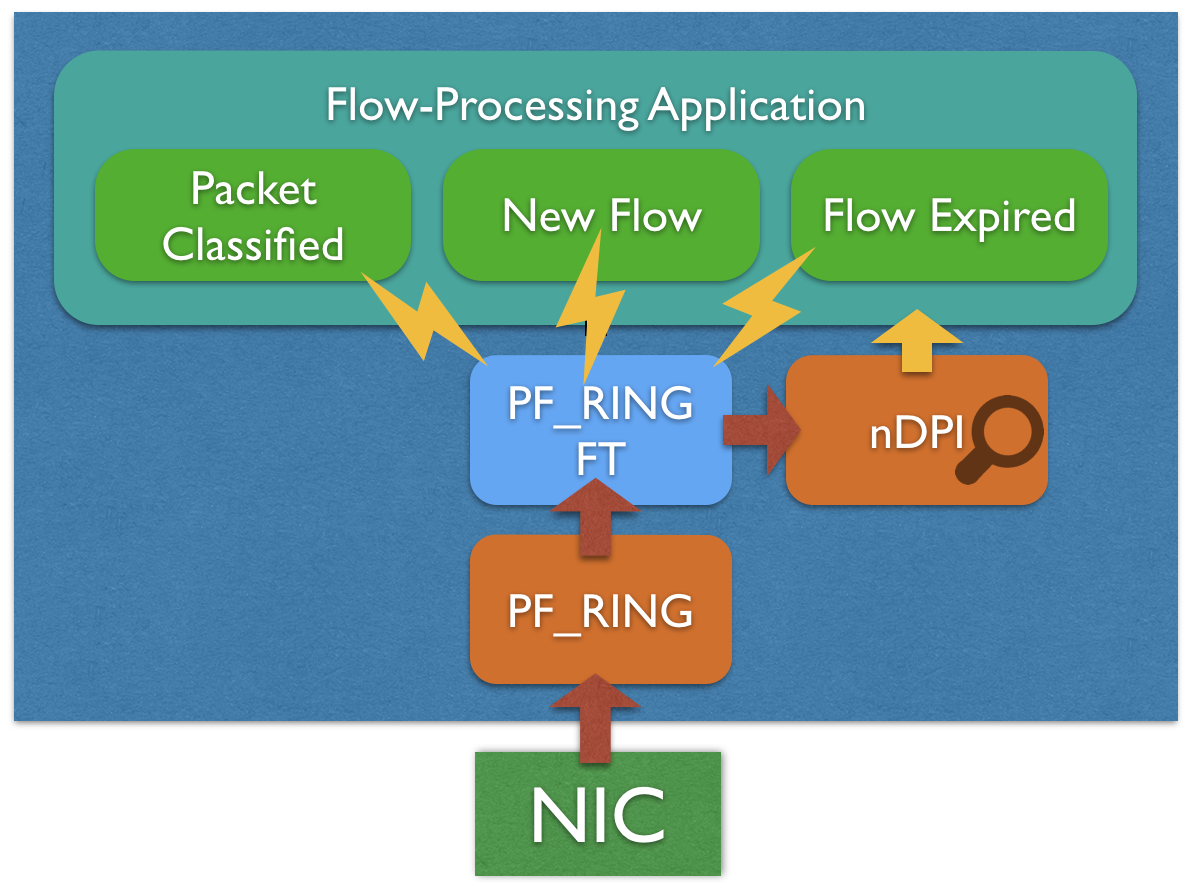
With PF_RING, and later on with PF_RING ZC (Zero Copy), we created a packet processing framework able to provide 1/10/100 Gbit line-rate packet capture to the applications, based both on commodity NICs or specialized FPGA adapters. This dramatically reduced the overhead for the first major task a network monitor application has to cope with, which is the packet capture. PF_RING also includes support for packet decoding, with the ability to leverage on metadata provided by the hardware to accelerate attributes extraction, first but not least the packet hash.
PF_RING FT is taking one step further: it assists the application in the flow classification activity. PF_RING FT implements a highly optimized flow table that can be used to keep track of flows and extract flow information up to L7. It provides many hooks to be able to customize and extend flow processing in order to build any type of application on top of it, including probes, IDSs, IPSs, L7 firewalls.
Although PF_RING FT is distributed with PF_RING, it is possible to use the library with any third-party packet capture framework such as Intel DPDK, as its data-ingestion API is capture-agnostic.
The designing and implementation of a flow processing application on top of PF_RING FT is quite straightforward. The code snippet below shows how to capture traffic and export flow information with PF_RING FT in a few lines of code.
ft = pfring_ft_create_table(0);
pfring_ft_set_flow_export_callback(ft, processFlow, NULL);
while (1) {
if (pfring_recv(pd, &packet, 0, &header, 0) > 0)
action = pfring_ft_process(ft, packet, &header);
}
void processFlow(pfring_ft_flow *flow, void *user){
pfring_ft_flow_key *k = pfring_ft_flow_get_key(flow);
pfring_ft_flow_value *v = pfring_ft_flow_get_value(flow);
/* flow export here with metadata in k and v */
}
The pfring_ft_set_flow_export_callback() API in the code snippet above is just an example of hook provided by PF_RING FT. Through this mechanism it is possible to get notified when a new flow is created, or a flow expired, or a packet has been successfully classified, or the L7 protocol has been identified.
PF_RING FT provides common flow information, that can be extended with custom metadata defined by the application. Thanks to a native integration with the nDPI library, the built-in information include the L7 protocol out of the box. The application itself does not need to deal with the nDPI library directly.
Suricata, Bro, Snort Acceleration
The PF_RING FT library also features a filtering/shunting mechanism that can be used to automatically, or through custom code, mark flows for filtering traffic. This can be used for instance for accelerating CPU-bound applications such as IDS/IPSs including Suricata, Bro and Snort, shunting flows based on the application protocol. In fact, discarding elephant flows is becoming a common practice for reducing the amount of traffic such applications need to inspect (typically multimedia traffic), dramatically reducing packet loss and improving the system performance. PF_RING FT is today used by PF_RING to implement L7 flow shunting, this means that PF_RING-based or Libpcap-based application can take advantage of this technology without changing a single line of application code.
Performance
As we have seen this library provides high flexibility and customization, however we also really care about the performance. Developing this library we applied all the lessons learnt while implementing PF_RING ZC and nProbe Cento, creating a highly optimized engine capable of processing 14.88 Mpps (10 Gbit line rate) on a single core of a Xeon E3-1230v5, and 130 Mpps on 12 cores of a Dual Xeon E5-2630v2 2.6Ghz (not the fastest CPU on the market), as you can se from the test results in the product page.
Learning PF_RING FT
If you want to learn more about PF_RING FT, you can go to the PF_RING repository and walk through our code examples. You will see how to use this technology also with non PF_RING packet processing libraries such as libpcap and DPDK. In essence you can now focus on solving your problem instead of addressing time-consuming tasks such as packet capture, decode and flow processing.