14. Flows Dump¶
Ntopng supports flows dump towards multiple downstream databases, namely MySQL, Elasticsearch, Syslog and ClickHouse. Flows dump is enabled using option -F.
Note
ClickHouse support is the recommended database backend used to dump flows and alerts.
When flows dump is enabled, a new Flow Dump Settings tab appears in the preferences.
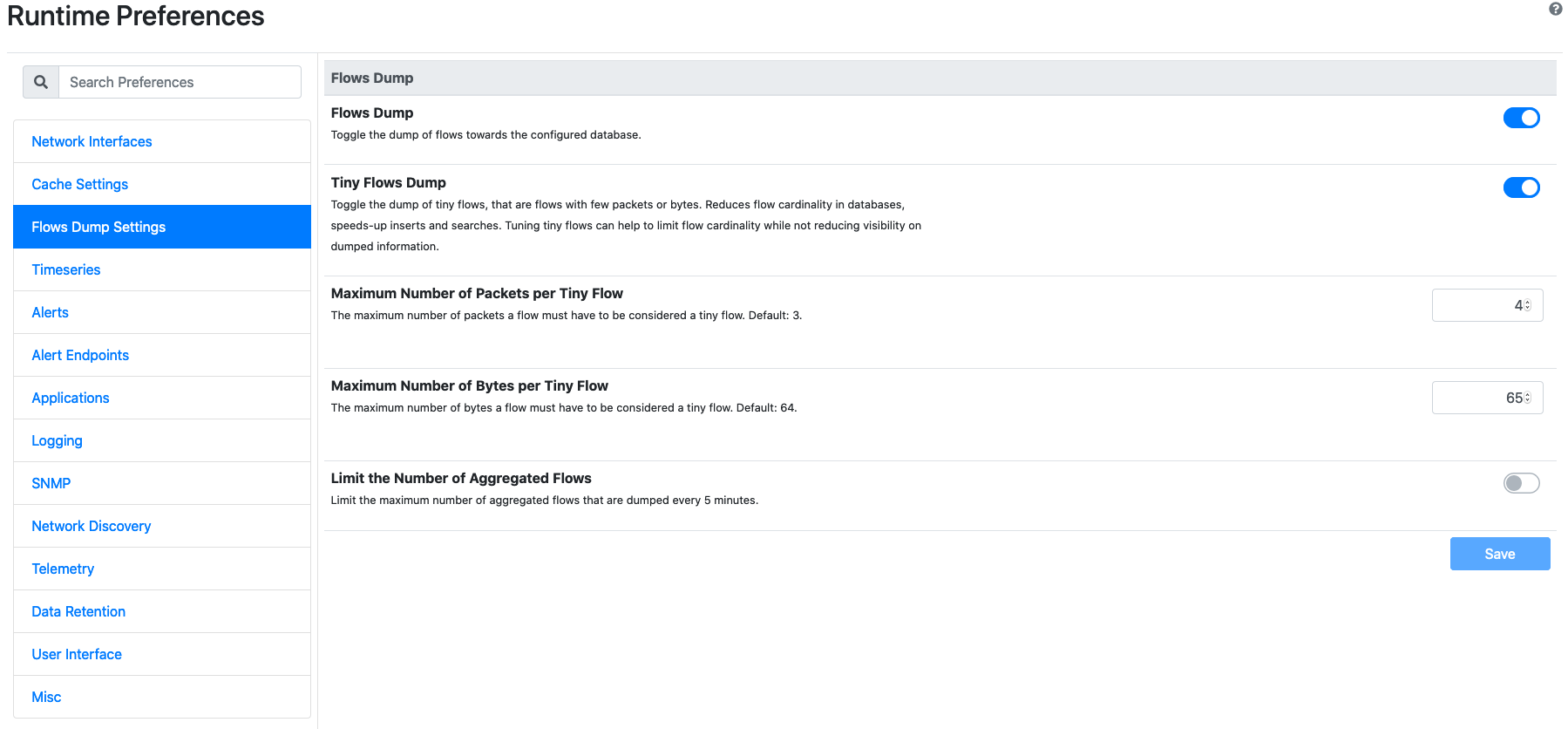
Flows Dump Settings
Flow Dump Settings entries are:
- Flows Dump: to toggle the dump of flows during the execution of ntopng. Flows dump can be turned on or off using this toggle. Turning flows dump off may be useful when the destination downstream database is running out of space, for debug purposes, or when the user only wants alerts stored in ElasticsearchAlerts.
- Tiny Flows Dump: to toggle the dump of tiny flows. Tiny flows are small flows, that is, flows totalling less than a certain configurable number of packets or bytes. Excluding tiny flows from the dump is an effective strategy to reduce the number of dumped flows. This reduction is mostly effective when dumped flows are used to do analyses based on the volume. It is not recommended to use this option when dumped flows are used for security analyses.
- Maximum Number of Packets per Tiny Flow: is used to configure the maximum number of packets a flow must have to be considered tiny.
- Maximum Number of Bytes per Tiny Flow: is used to configure the maximum number of bytes a flow must have to be considered tiny.
- Limit the Number of Aggregated Flows: allows to cap the number of aggregated flows dumped periodically when using nIndex or MySQL. MySQL and nIndex aggregate flows at 5-minute intervals to make certain queries faster. Reducing the number of aggregated flows may be useful to reduce the total number of exports performed and thus, the number of aggregated flows in the database.
- Maximum Number of Aggregated Flows Dumped Every 5 Minutes: is used to specify the maximum number of aggregated flows dumped every 5-minutes.
These settings are effective for all databases.
14.1. ClickHouse¶
ntopng integrates with ClickHouse to store historical flows and alerts. ClickHouse is an high-performance SQL database. See ClickHouse (Flow Dump) for a detailed discussion and guide.
14.2. ElasticSearch¶
Elasticsearch is an Open-Source real-time search and analytics engine with a powerful RESTful API built on top of Apache Lucene. Ntopng can connect to an external Elasticsearch cluster as client using the Bulk insert API for JSON mapped indexing.
Elasticsearch is designed for quickly and dynamically analyzing or searching through large amounts of data and thus is ideal for flows generated by ntopng, enabling users and integrators to create a virtually infinite number and variety of statistics using Kibana.
To learn more about Elasticsearch visit: https://www.elastic.co/guide.
To dump expired flows to Elasticsearch ntopng requires the -F modifier followed by a string in the following format:
es;<idx type>;<idx name>;<es URL>;<http auth>
The string has 5 semi-colon separated fields
- es instructs ntopng to dump flows to Elasticsearch
- <idx type> “_type” to use in exported documents
- <idx name> index to use for exported documents [ accepts strftime() format ]
- <es URL> URL of Elasticsearch Bulk API [ ie: http://127.0.0.1:9200/bulk]
- <http auth> Basic HTTP Authentication [ username:password ]
Example:
es;ntopng;ntopng-%Y.%m.%d;http://localhost:9200/_bulk;
Definitions:
Indexes are like ‘databases’ in a RDBMS terms. An index is a logical namespace which maps to one or more primary shards and can have zero or more replica shards distributed across nodes of a cluster. Index mapping defines the multiple supported types.
Mapping is required for Elasticsearch to correctly interpret all fields produced by ntopng, specifically those containing IP and Geo Location data. This is achieved by using a mapping template for ntop types, automatically inserted by the application at startup. Note this action requires full admin rights on the cluster in order to be performed successfully.
Ntopng will create Indexes and Mapping automatically on startup with no action required. Each time the index name changes, a new Index is created. By default, ntopng creates one daily index (i.e.: ntopng-2015.11.21). Index types can be used to differentiate instances.
Data Rotation:
The official Curator tool from Elastic can be used to manage and rotate Indexes created by ntopng according to the user preferences and requirements.
14.3. Syslog¶
To dump flows to Syslog, specify -F="syslog". Flows are dumped to Syslog in JSON format.
This allows external applications to consume dumped flows easily, and it simplifies the delivery of flows
to downstream applications such as Logstash.
An example of flow dumped to Syslog is the following
{ "IPV4_SRC_ADDR": "192.168.2.222", "SRC_ADDR_LOCAL": true, "SRC_ADDR_BLACKLISTED": false, "SRC_ADDR_SERVICES": 0, "IPV4_DST_ADDR": "192.168.2.1", "DST_ADDR_LOCAL": true, "DST_ADDR_BLACKLISTED": false, "DST_ADDR_SERVICES": 0, "SRC_TOS": 0, "DST_TOS": 0, "L4_SRC_PORT": 38294, "L4_DST_PORT": 22, "PROTOCOL": 6, "L7_PROTO": 92, "L7_PROTO_NAME": "SSH", "TCP_FLAGS": 31, "IN_PKTS": 7, "IN_BYTES": 471, "OUT_PKTS": 5, "OUT_BYTES": 2028, "FIRST_SWITCHED": 1610381756, "LAST_SWITCHED": 1610381756, "CLIENT_NW_LATENCY_MS": 0.010000, "SERVER_NW_LATENCY_MS": 0.205000, "SRC_IP_COUNTRY": "", "SRC_IP_LOCATION": [ 0.000000, 0.000000 ], "DST_IP_COUNTRY": "", "DST_IP_LOCATION": [ 0.000000, 0.000000 ], "NTOPNG_INSTANCE_NAME": "devel", "INTERFACE": "eno1" }
Packaged versions of ntopng install a rule in /etc/rsyslog.d/20-ntopng.conf to dump flows and all other ntopng-generated Syslog logs to /var/log/ntopng.log.
This behavior can be changed by editing or removing /etc/rsyslog.d/20-ntopng.conf.
To process or see all ntopng-generated Syslog logs, the file /var/log/ntopng.log can be accessed directly. On systemd-based systems, such logs
can be accessed also using the journalctl facility. For example, to get all the logs of ntopng running as daemon, one can run
$ sudo journalctl -u ntopng
Warning
In case /var/log/ntopng.log is edited/removed manually, service rsyslogd may need a restart. To restart rsyslogd type in a console sudo service rsyslog restart
Note
Syslog flows dump is not available on Windows