Overview
Those of you who have some experience with IDS or IPS systems, like Zeek and Suricata, are probably aware of how CPU intensive and memory consuming those applications are due to the nature of the activities they carry on (e.g. signatures matching). This leads to high system load and packet loss when the packet rate becomes high (10+ Gbi+) making these IDSs unlikely to be to deployed on high-speed networks. As nProbe Cento can analyse networks up to 100 Gbit while using nDPI for ETA (Encrypted Traffic Analysis), ntopng can act as a Cento collector to receive and consolidate flow information as well identify attackers and victims hosts. This blog post shows you how using ntop tools it is possible to enable Zeek and Suricata “on demand”, i.e. limited to those attackers or host victims. This means that:
- nProbe Cento is started to poll all network traffic on top of a network adapter able to support hardware filters such as nVidia Connect-X.
- Zeek and/or Suricata are started with a hardware filter that does not send them any traffic.
- As soon as ntopng detects an attacker/victim host, it writes its IP in a redis queue that is polled by PF_RING.
- As soon as PF_RING detects an IP to ban/unban it adds a hardware filtering rule on the “on demand” connection, so such IP traffic is sent to Zeek/Suricata
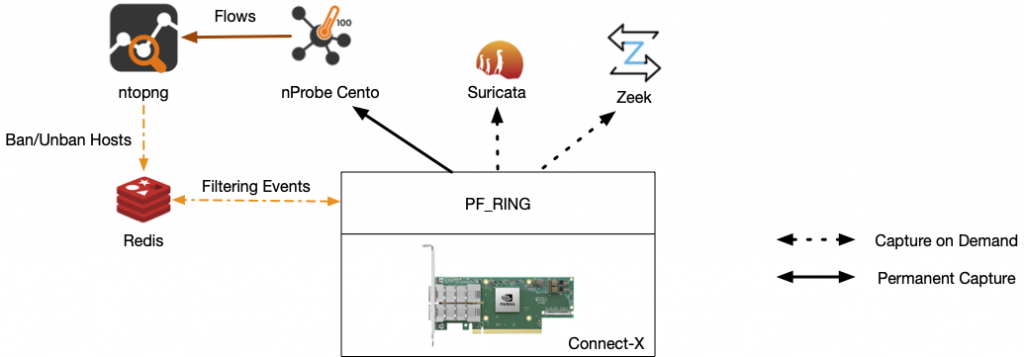
Going Deep
The PF_RING framework has demonstrated to play a key role in the acceleration of those tools, by delivering features like:
- packet capture acceleration, to deliver line-rate capture speed and make more CPU cycles available to the tools (if interested please read the IDS/IPS Integration section of the PF_RING documentation)
- filtering, to reduce the input by (statically) defining filtering policies from Layer 2 up to Layer 7, dramatically improving the performance of the tools (please read the PF_RING FT acceleration section).
Recently, a new technique has been introduced in PF_RING and ntopng for accelerating IDS systems, whose idea is similar to the Smart Recording acceleration used by n2disk and described in a previous post and video tutorial. In fact, in order to save resources (that can be disk space in case of n2disk, or CPU cycles in case of an IDS), the best approach is to run the tools on-demand on interesting traffic only.
How to do this? ntopng implements Behavioural checks that can detect when a host is misbehaving (as well as classic attacks such as port scans, brute force or invalid protocol requests) , and can be configured to push information about those hosts to external tools for further analysing their traffic.
PF_RING 8.5 (or later) includes native support for runtime filtering, which is the ability to add filtering rules while the application is running. Filtering rules are automatically converted into hardware rules and offloaded to the adapter, to be evaluated in hardware and add zero overhead (available on adapters supporting hardware filtering like the NVIDIA ConnectX). This allows you to run an IDS and receive only selected traffic (only packets matching hosts that require attention), according to rules which are dynamically built and pushed to the capture engine. Please note that unlike other adapter families (e.g. Intel), with nVidia multiple applications can simultaneously open the same network adapter and apply hardware filtering rules selectively (i.e. adding a filter on a connection does not discard packets on the other connections as hardware filters are per connection and not per NIC).
Let’s see how this works under the hood.
Filters are pushed to the capture engine by means of a Redis queue. Host filters can be added and removed by means of commands like “add host” or “remove host”.
This can be configured in ntopng from the Interface > Details > Settings menu, where it is possible to toggle the Push Alerted Hosts to PF_RING flag.
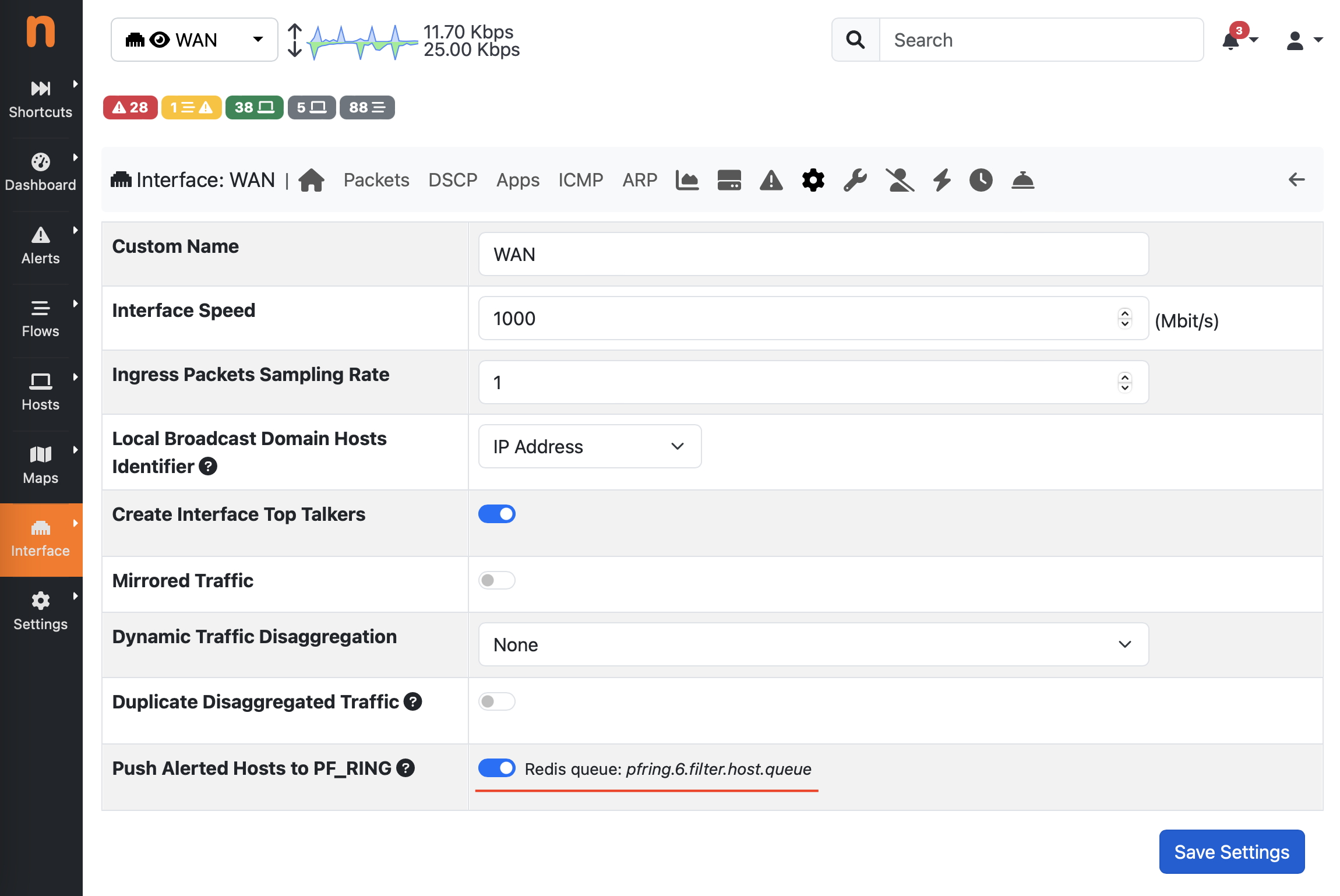
With this setting enabled, ntopng notifies hosts for which there is an engaged alert to PF_RING, triggering the diversion of the traffic matching those hosts to the IDS (or any other application running on top of PF_RING), which is otherwise discarded by default.
The name of the Redis queue is pfring.ID.filter.host.queue and it’s reported by the GUI (more details about this queue and how it works are available in the PF_RING Runtime Filtering section of the PF_RING user’s guide=.
In order to run the application on top of PF_RING, and enable Runtime Filtering, the PF_RING_RUNTIME_MANAGER environment variable should be set, using as value the name of the Redis queue used by ntopng to push the filtering commands.
Example with Suricata on top of a NVIDIA/Mellanox adapter:
PF_RING_RUNTIME_MANAGER="pfring.6.filter.host.queue" suricata --pfring-int=mlx:mlx5_0 -c /etc/suricata/suricata.yaml
Obviously, Suricata should be compiled with PF_RING support, please refer to the IDS/IPS Integration section of the PF_RING user’s guide for instructions.
As of Zeek you need to compile it using the libpcap library part of PF_RING as explained in the user’s guide and it will work as Suricata.
Final Remarks
Thanks to the above solution, it is now possible to enable IDSs on demand as soon as an issue is detected by nDPI/nProbe Cento/ntopng. This solution allows Suricata/Zeek to scale at 40/100 Gbit speeds that otherwise would be too high for such tools. We are aware that this solution relies on the ability of ntopng to detect attacks whereas it would have been desirable to run Suricata/Zeek on all network traffic. This can be achieved at a high cost (e.g. partitioning ingress traffic across multiple hosts that run such IDSs) also generating a lot of logs that would probably be too much to handle. We believe that the above solution is a reasonable compromise between speed, costs, and detection accuracy.
Do not forget that using the architecture described above it is possible to selectively enable from the command line (e.g. ‘redis-cli lpush “+1.2.3.4/32” pfring.6.filter.host.queue’) traffic analysis of selected hosts. This can also be a great solution for discarding in hardware all traffic except the one for critical hosts that instead need to be monitored permanently with an IDS regarded them being under attack or not.
Enjoy!