We often receive inquiries about the best practices for deploying nProbe and ntopng. This post will try to shed some light on this subject. The first thing to know is how many flows/second in total the nProbe instances will deliver to ntopng.
nProbe Flow Collection
Each nProbe instance can collect a high number of flows (in the 50/100k flows/sec range depending on hardware and flow types), but we typically suggest loading balance flows across multiple instances. Ideally, each nProbe instance should handle no more than 25k flow/sec. As ntop licenses are host-based, you can spawn multiple nProbe instances on the same host on different collection ports and share the workload. You can refer to the nProbe manual for learning how to start multiple nProbe services.
ntopng Flow Processing
If multiple nProbe instances send flows to the same ntopng, you should use different virtual collection interfaces in order to load share the workload. You need to define one virtual interface per nProbe instance and eventually aggregate all these interfaces into a single view interface in order to see everything from a single location. The ntopng user’s guide shows how to do this, but we invite all to show the example later in this post.
Historical Flows
ntopng can optionally (ntopng Enterprise M or superior required) dump flows into ClickHouse for implementing historical searches. If your hardware is adequate, you can choose to deploy nProbe+ntopng+ClickHouse onto the same host. Typically, this setup is suggested if you have a relatively small network (up to 25k flows/sec), whereas for a larger number of flows/sec, we suggest you use a host for nProbe+ntopng and another host (with at least 64 GB+ of RAM for speedy queries) fo ClickHouse. Remember that the ClickHouse retention requires disk space (typically a NetFlow record takes about 60 bytes on ClickHouse) for long data retention, whereas ntopng uses disk only for timeseries (no disk is used by nProbe except for dumping logs).
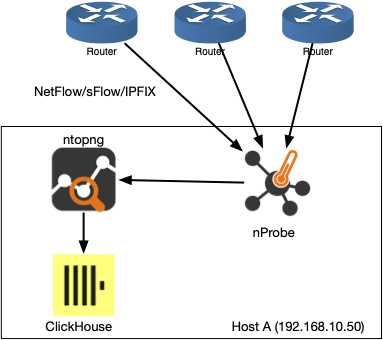
Use Cases: Small to Mid-Size Network
One nProbe and one ntopng instance are enough. They can be deployed on the same host with 64+ GB of memory and 1 TB of disk space. This host will also run ClickHouse.
Supposedly to collect flows on port 2055, below you can find some configuration files.
/etc/nprobe/nprobe.conf
-i=2055
--zmq=tcp://127.0.0.1:1234
/etc/ntopng/ntopng.conf
-i=tcp://127.0.0.1:1234
-F=clickhouse
Use Cases: Mid to Large Network
In this case, you need to load-balance the traffic across multiple nProbe instances (each one collecting flows on different ports) that send flows to the same ntopng. These apps can be deployed on the same host with 128+ GB of memory (more memory means better ClickHouse performance) and 1 TB of disk space. This host will also run ClickHouse, but if you want to do a clean design, you should run ClickHouse on a separate host (in the example below, it is 192.168.10.100).
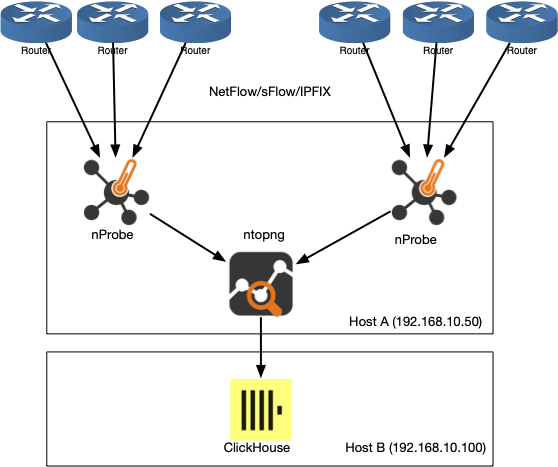
Supposing you want to collect flows on ports 2055 and 2056, below you can find some configuration files.
/etc/nprobe/nprobe-2055.conf
-i=2055
--zmq=tcp://127.0.0.1:1234
/etc/nprobe/nprobe-2056.conf
-i=2056
--zmq=tcp://127.0.0.1:1235
/etc/ntopng/ntopng.conf
-i=tcp://127.0.0.1:1234
-i=tcp://127.0.0.1:1235
-i=view:all
-F=clickhouse;192.168.10.100;ntopng;default;
For larger networks, you can deploy nProbe on a separate host(s) with respect to ntopng if CPU+memory re not enough for your project. There is not a rule of thumb, unfortunately, but the idea is to spread the load across cores/hosts in order to evenly balance the workload instead of collapsing everything on the same host.
Shall you have questions or unique needs, please feel free to contact us or discuss this on our community channels.
Enjoy !