Apache Kafka can be used across an organization to collect data from multiple sources and make them available in standard format to multiple consumers, including Hadoop, Apache HBase, and Apache Solr. nProbe — and it’s ultra-high-speed sibling nProbe cento — integration with the Kafka messaging system makes them good candidates source of network data. The delivery of network data to a redundant, scalable, and fault-tolerant messaging system such as Kafka enables companies to protect their data even in-flight, that is, when the consolidation in a database has still to occur.
An impatient reader who is eager to use Cento for delivering flows to a Kafka cluster having a broker at address 127.0.0.1:9092 on a topic named “topicFlow can use the following command
ntopPC:~/code/cento$ ./cento -i eth0 --kafka “127.0.0.1:9092;topicFlows"
Readers who are interested in learning more about Cento and Kafka should continue reading this article that starts by describing Cento-Kafka publishing mechanisms and then moves to a real configuration example. Finally, in the appendix, it describes how to setup Kafka both in a single- and multi-broker fashion.
Cento will be used in the remainder of this article to carry on the discussion. Examples and configurations given work, mutatis mutandis, also for nProbe.
Publishing nProbe Cento Flows to Kafka
Cento publish flow “messages” into a Kafka cluster by sending them to one or more Kafka brokers responsible for a given topic. Both the topic and the list of Kafka brokers are submitted using a command line option. Initially, Cento tries to contact one or more user-specified brokers to retrieve Kafka cluster metadata. Metadata include, among other things, the full list of brokers available in the cluster that are responsible for a given topic, and the available topic partitions. Cento will use the retrieved full list of brokers to push flow “messages” in a round robin fashion to the various partitions.
Cento also features optional message compression and message acknowledgement policy specification. Acknowledgment policies make it possible to totally avoid waiting for acknowledgements, to wait only for the Kafka leader acknowledgement, or to wait for an acknowledgment from every replica.
Setting Up Cento
Let’s say Cento has to monitor interface eth1 and has to export generated flows to Kafka topic “topicFlows”. The following command will do the magic
ntopPC:~/code/cento$ ./cento -i eth0 --kafka “127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094;topicFlows"
The command above assumes flows have to be exported on topic topicFlows and that there are three brokers listening on localhost, on ports 9092, 9093 and 9094 respectively. These Kafka brokers are shown also in the picture below together with the running Cento instance
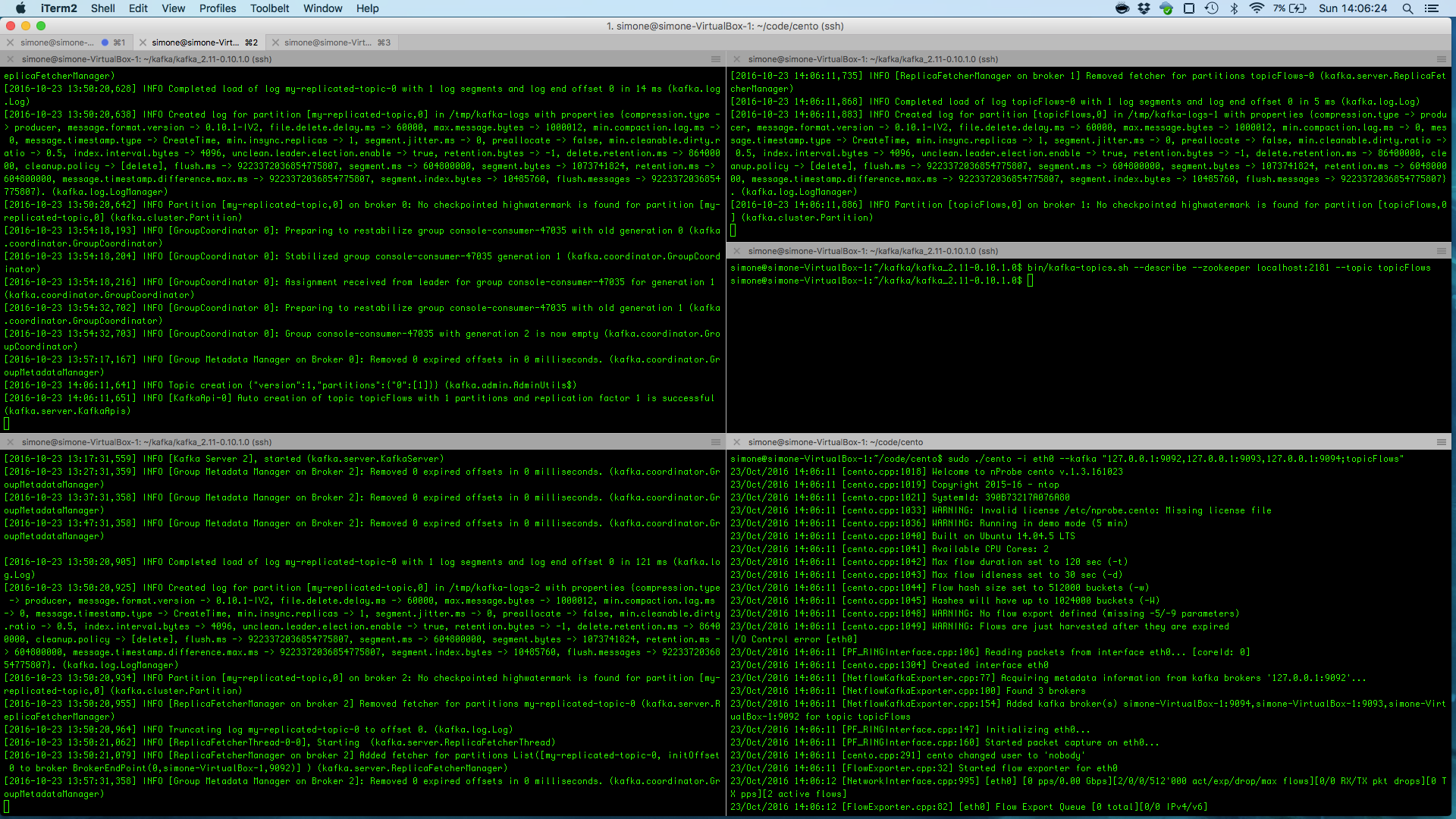
Consuming Cento Flows
For the sake of example, the command-line script kafka-console-consumer.sh available in the bin/ folder of the Kafka sources is used to read messages from a Kafka topic (see the appendix for instructions on how to get it). In order to consume flows in the topicFlows we can use the command line-script as follows
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topicFlows --from-beginning
Below is an image that shows flows that are being consumed from the Kafka cluster.
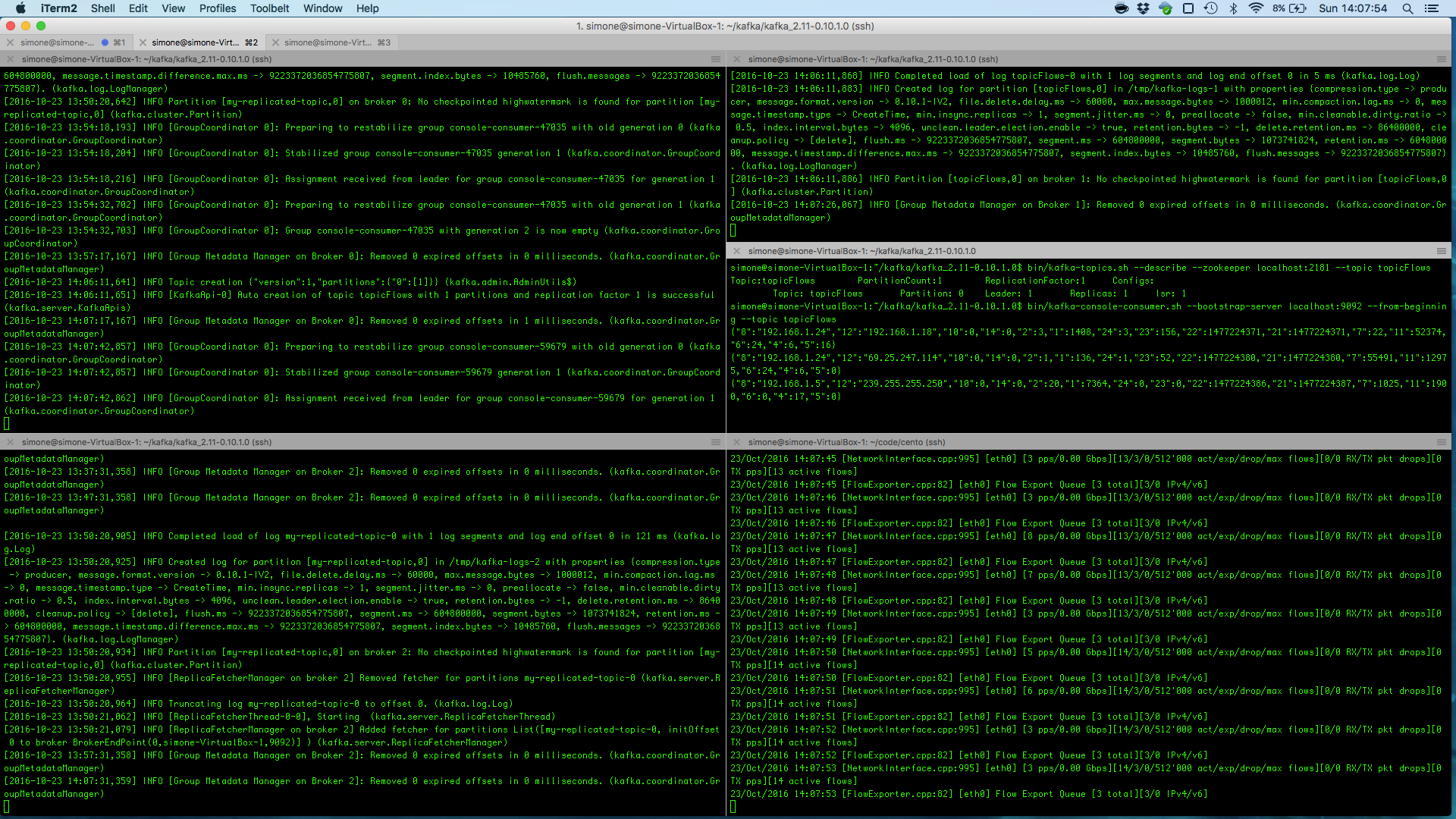
Note that flows can be consumed by any custom application that can interact with Kafka.
Cento and Kafka Topics
Cento takes as input a topic, that is, a string representing the generated stream of data inside Kafka. Topics can be partitioned and replicated. With reference to the topic being used, Cento has the following behavior:
- If the topic doesn’t exist in the Kafka cluster, then Cento creates it with a single partition and replication factor 1
- If the topic exists in the Kafka cluster, then Cento uses the existing topic and will send flows to the whole set of partitions in round-robin.
So, if the user is OK with a single-partition topic can simply fire up Cento that will create it. If more complex topic configurations are needed, then the topic has to be created in advance using, for example, the helper script kafka-topics.sh. We refer the interested reader to the remainder of this section for a detailed discussion on the Kafka setup and its topics.
Appendix
Setting Up Kafka
Prerequisites
Getting Kafka
The latest version of Kafka can be downloaded from https://kafka.apache.org/downloads. Download the latest tar archive (kafka_2.11-0.10.1.0.tgz at the time of writing), extract it, and navigate into the decompressed folder.
ntopPC:wget http://apache.panu.it/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz ntopPC:~/kafka$ tar xfvz kafka_2.11-0.10.1.0.tgz ntopPC:~/kafka$ cd kafka_2.11-0.10.1.0/ ntopPC:~/kafka/kafka_2.11-0.10.1.0$ ls bin config libs LICENSE logs NOTICE site-docs
Starting Zookeeper
Kafka uses Zookeeper to store a great deal of status information that includes, but is not limited to, the topics managed by each broker. An healthy Zookeeper installation consists of at least three distributed nodes. In this example, we will just start a quick-and-dirty zookeeper on the same machine that will run Kafka. This represents a single point of failure and should be absolutely avoided in production environments.
To start the zookeeper we can simply use the one that is shipped with Kafka as follows
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ ./bin/zookeeper-server-start.sh config/zookeeper.properties [...] [2016-10-23 12:50:02,402] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
Starting a Kafka Broker
Now that Zookeeper is up and running it is possible to start a Kafka broker by using the default configuration found under config/server.properties. Upon startup, the broker will contact the Zookeeper instance to exchange and agree on some status variables.
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ ./bin/kafka-server-start.sh config/server.properties [...] [2016-10-23 12:52:01,510] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
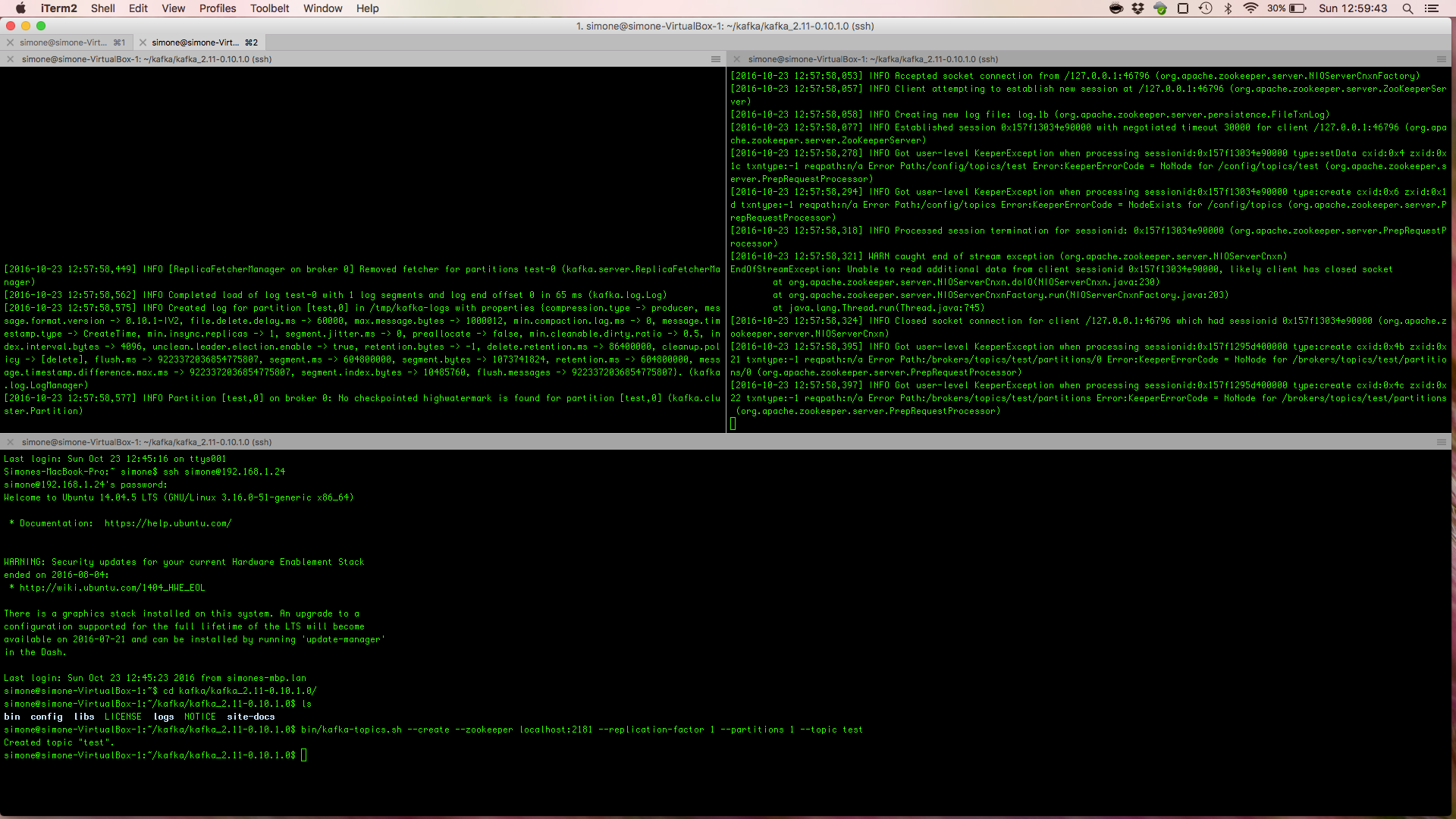
Creating a Kafka test Topic
A simple test Kafka topic with just one partition an replication factor 1 can be created using the kafka-topics.sh helper script.
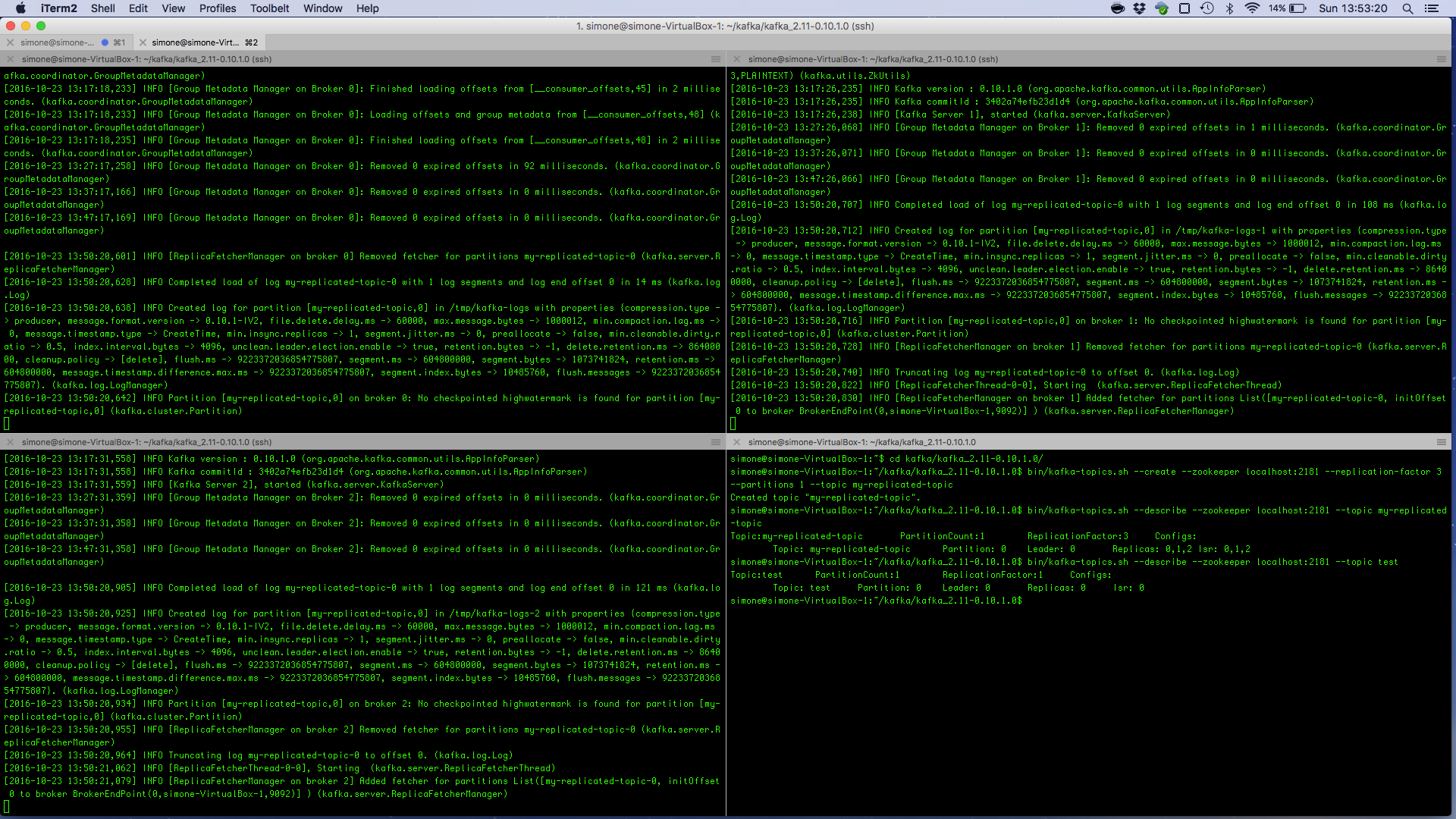
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Graphically, topic creation is show in the following image.
Producing Messages on a test Topic
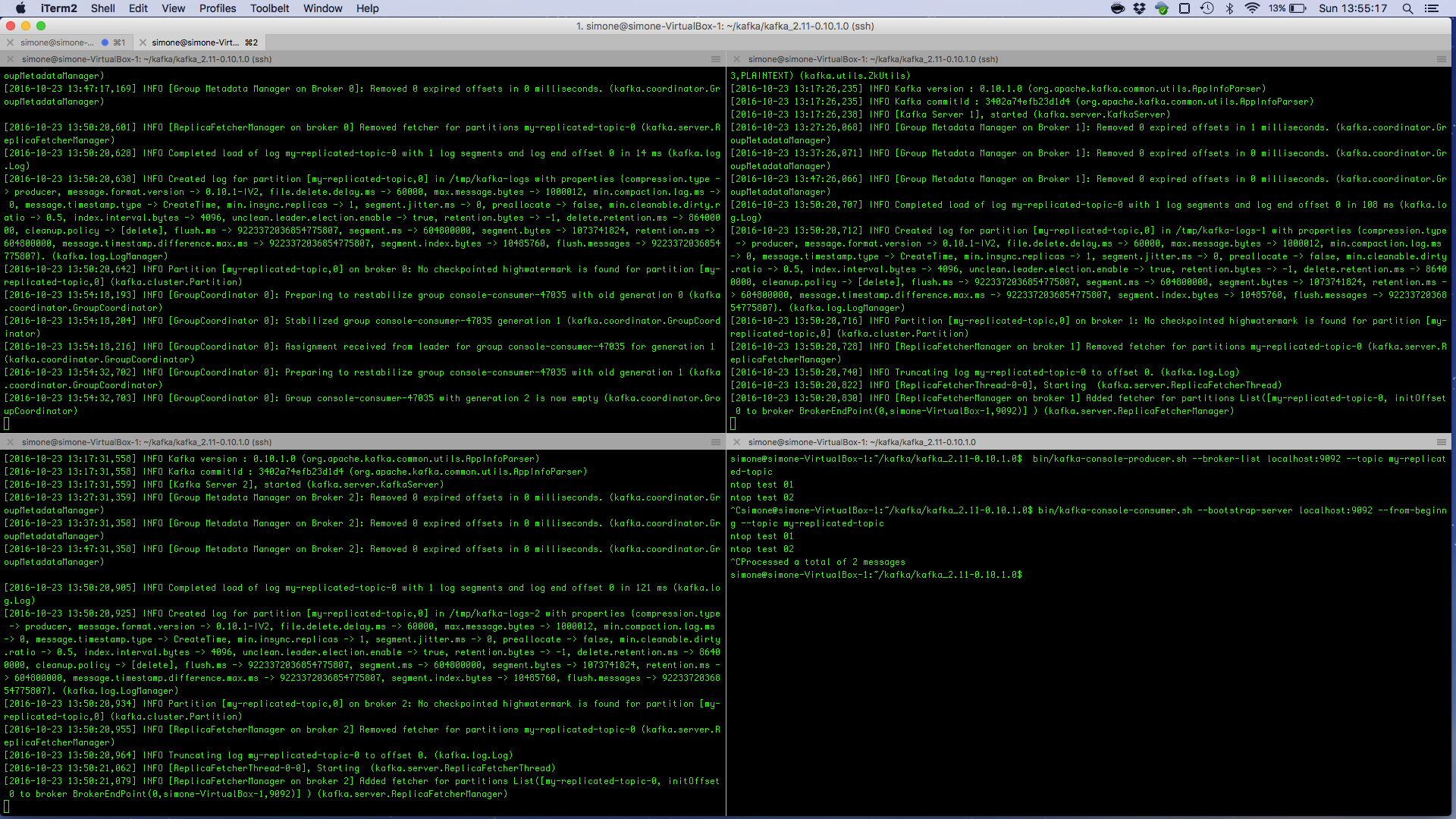
A command-line producer available in the bin/ folder can be used to test and see if the Kafka deployment can receive messages. The script will send messages (one per line) unless Ctrl+C is pressed to exit. In the following example two “ntop test” messages are produced and sent to the broker listening on localhost port 9092.
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test ntop test 01 ntop test 02
Consuming messages on a test Topic
A command-line consumer available in the bin/ folder can be used to read messages from a Kafka topic. In the following snippet the script is used to consume the two “ntop test” messages produced above. The script will wait for new messages until Ctrl+C will be pressed to exit.
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning ntop test 01 ntop test 02
Following is an image that shows how to consume messages from the topic.
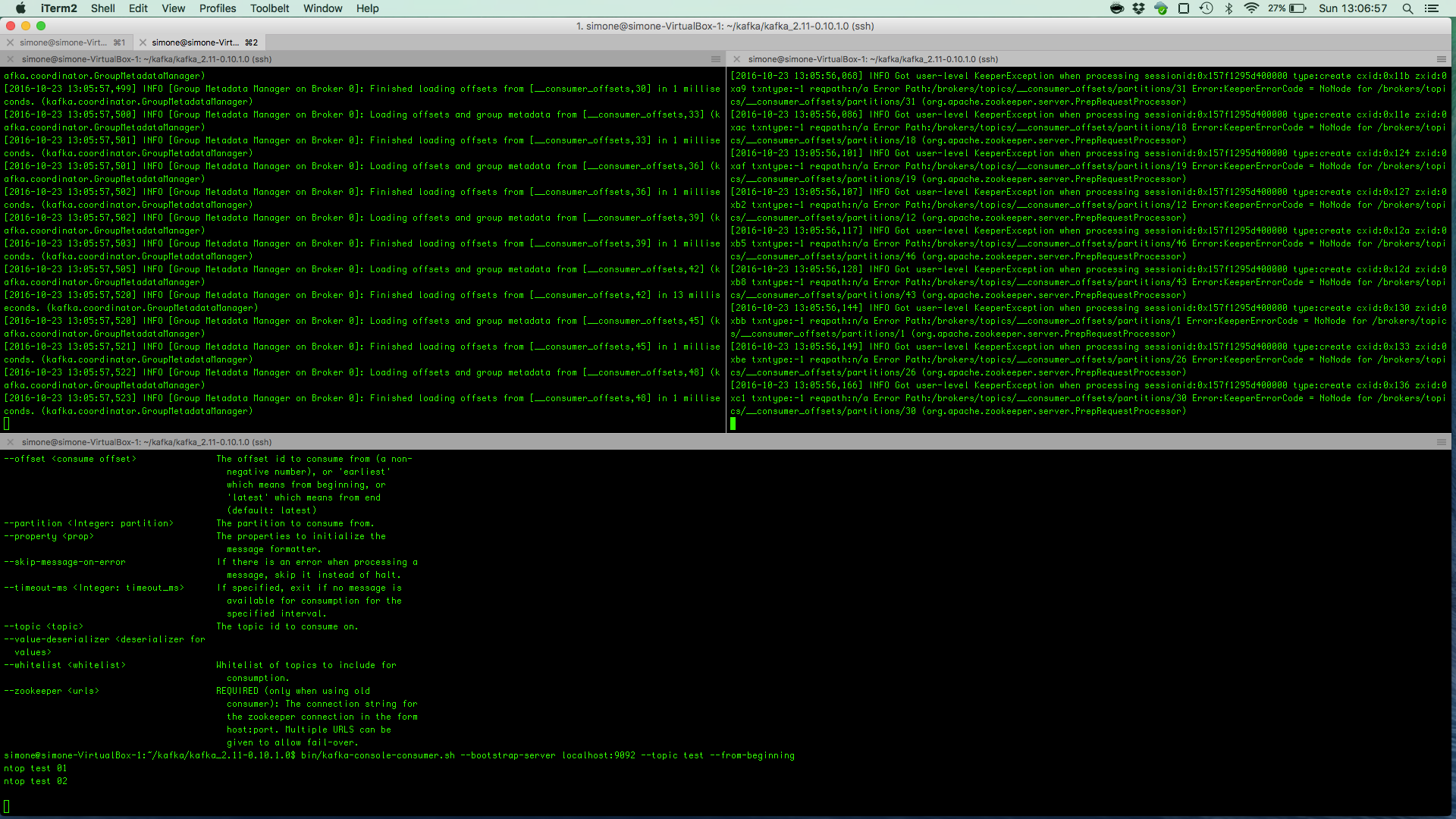
Bottom: The command-line consumer
Multi-Broker
A real Kafka cluster consist of multiple brokers. In the remainder of this section is is shown how to add two extra Kafka brokers to the cluster that is already running the broker started above. In order to add the two kafka brokers two configuration files must be created. They can be copied from the default configuration file found in config/server.properties.
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ cp config/server.properties config/server-1.properties ntopPC:~/kafka/kafka_2.11-0.10.1.0$ cp config/server.properties config/server-2.properties
The two files will carry configuration information for two different brokers:
- server-1.properties configures a broker as follows: broker id 1; listen on localhost port 9092 and log in /tmp/kafka-logs-1
- server-2.properties configures a broker as follows: broker id 2; listen on localhost port 9093 and log in /tmp/kafka-logs-2
The relevant part of the configuration files is the following.
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ cat config/server-{1,2}.properties | egrep '(id|listeners|logs)'
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# listeners = security_protocol://host_name:port
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9093
# it uses the value for "listeners" if configured. Otherwise, it will use the value
#advertised.listeners=PLAINTEXT://your.host.name:9092
log.dirs=/tmp/kafka-logs-1
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# listeners = security_protocol://host_name:port
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9094
# it uses the value for "listeners" if configured. Otherwise, it will use the value
#advertised.listeners=PLAINTEXT://your.host.name:9092
log.dirs=/tmp/kafka-logs-2
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
The two additional brokers can be started normally. They will discover each other — and the already running broker — through the Zookeeper.
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ bin/kafka-server-start.sh config/server-1.properties ntopPC:~/kafka/kafka_2.11-0.10.1.0$ bin/kafka-server-start.sh config/server-2.properties
Creating a Partitioned Topic
A replicated test topic named “topicFlowsPartitioned” can be created using the kafka-topic.sh helper script. Once created, the status of the topic can be queried using the same helper.
ntopPC:~/kafka/kafka_2.11-0.10.1.0$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic topicFlowsPartitioned Created topic "topicFlowsPartitioned". ntopPC:~/kafka/kafka_2.11-0.10.1.0$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic topicFlowsPartitioned Topic:topicFlowsPartitioned PartitionCount:3 ReplicationFactor:3 Configs: Topic: topicFlowsPartitioned Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0 Topic: topicFlowsPartitioned Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1 Topic: topicFlowsPartitioned Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
The creation of the partitioned topic is also shown in the image below
Producing and consuming messages on the replicated topic can be done exactly as it has already been shown for the single topic. The following image shows the usage of producer and consumer scripts execution
References
- Kafka documentation: https://kafka.apache.org/documentation