PF_RING is a packet capture framework which accelerates packet capture and transmission on any adapter. In addition to pure packet capture acceleration, it provides additional features including packet parsing, filtering, load-balancing and many other functionalities to assist a packet processing application.
PF_RING interacts with the Linux stack by implementing a new type of network socket that improves the packet capture speed and it also captures packets more efficiently preserving CPU cycles that can be used by the application for the real processing.
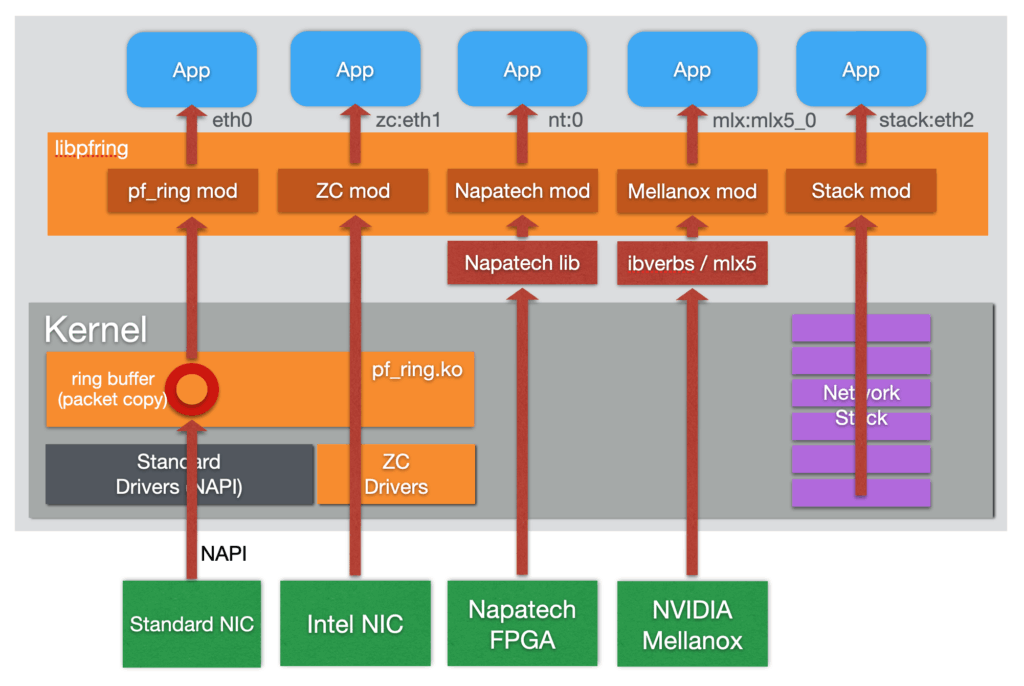
PF_RING has a modular architecture that makes it possible to use additional components other than the standard PF_RING kernel module. Currently, the set of additional modules includes:
- ZC module.
This module supports zero-copy capture with Intel, NVIDIA/Mellanox, and FPGA adapters including Napatech and Silicom/Fiberblaze. Have a look at the PF_RING ZC page for additional information. - Stack module.
This module can be used to inject packets to the linux network stack. - Timeline module.
This module can be used to seamlessly extract traffic from a n2disk dump set using the PF_RING API.

at a glance
Key Features
- Linux network socket available for all kernels (latest kernels for the most common Linux distributions are officially supported)
- DKMS support and no need to patch the Linux kernel (a kernel module is automatically loaded)
- Agnostic API for device driver independent application code
- Kernel-based packet capture for all adapter models
- Libpcap support for seamless integration with existing pcap-based applications
- Optimized nBPF filters in addition to the legacy BPF
Enable PF_RING Zero-Copy for line-rate performance!
PF_RING ZC drivers implement Zero-Copy packet capture and transmission for performance at 100+ Gbit/s and the lowest CPU overhead, in addition to enhanced offloads (filtering, timestamping, load-balancing, ...).
Ideal for Every Environment
Use Cases
Packet Capture Acceleration
PF_RING dramatically enhances packet capture performance, making it ideal for building scalable network monitoring solutions. Whether for flow analysis, traffic accounting, or deep packet inspection, PF_RING ensures minimal packet loss even at multi-gigabit speeds, and above 100 Gbit with zero-copy drivers.
Inline Applications
Security tools like Suricata and Zeek integrate seamlessly with PF_RING to process high-speed traffic efficiently. This enables real-time threat detection and mitigation without sacrificing packet capture accuracy or system performance.
Traffic Replay and Generation
PF_RING enables accurate PCAP traffic replay and high-performance synthetic traffic generation for lab testing, benchmarking, and QA environments. It allows teams to emulate real-world conditions and validate the behavior of network appliances, security systems, and applications under controlled scenarios.
Specifications
Tech Specs
models
Choose Your Model
Already included in all ntop applications.
Open Source
- Kernel-based acceleration
- Support for all Network adapters
- Packet headers parsing
- Kernel-based clustering and load-balancing
- In-kernel software filters and BPF
- Source code available on GitHub