In v4 we have introduced active monitoring in ntopng and since then we are improving in the 4.1.x development versions. In order to enable it you have to selectd the “System” interface from the top menubar and select “Active Monitoring” from the left “System” menu.
On that page you will see a table containing all your measurements. The code has been written in a modular way, so that available measurements can be extended as necessary simply adding a new lua script. As you can see from the measurements source, you simply have to create a new lua file for performing the measurement and throw it in the measurement folder for being executed.

Currently the following measurement families are supported:
- ICMP ping: send a scheduled ping (e.g. every minute) and measure the RTT (Round Trip Time).
- Continuous ICMP ping: same as above ping but continuous (send a ping every 3 seconds) to better evaluate continuous network reachability and thus service availability.
- Speedtest: evaluates the available bandwidth (up and down) as well the latency using the speedtest.net service.
- HTTP/HTTPS: periodic test HTTP(S) availability by contacting a remote web server.
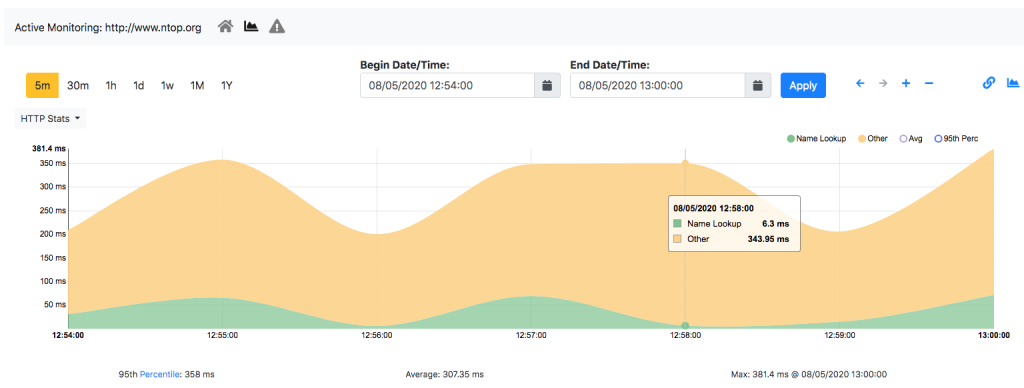
The goal of the above measurements is to perform periodic activities and trigger alerts when something goes wrong.

For every measurement there is a threshold that is checked and in case the measurement does not satisfy the threshold, an alarm is triggered.

Such alarm stays open until the problem is solved that happens when the measurement is under the threshold. Note that for certain measurements such as continuous ping the threshold is an upper threshold: as the goal of this test is to continuously monitor service availability (measured as the number of successful ping replies with respect to issued ping requests), in this case this is an upper threshold (i.e. trigger an alert when availability goes below a certain threshold).
This is the current state of the art. What we’re trying to do is implement flexible alert generation. This means that we would like to alert selected recipients for a given alarm (today we alert all recipients the same way, instead of alerting recipient A for measurement X, and recipients B,C for measurement Y), and execute for instance a recovery action when something goes wrong.
Furthermore we’re working at additional measurements and we would like our community to contribute: please raise your hand.
Enjoy!