Being able to store network flows is a very challenging task using generic databases. Networks are becoming faster and faster and, nowadays, flow-based analysis tools should store tens, or even hundreds, of thousands of flows per second, to keep up with SME and enterprise demands. Existing tools, such as relational databases, fail to accomplish this task. Unless you have unlimited resources available, tons of RAM and clusters of machines, chances are your database will choke, quickly becoming too slow to enable queries from being performed in a reasonable time. It was incredible the number of users complaining of slow MySQL instances that both slow when ingesting flows and also when performing queries for the analysis.
Another option many people use is the so called big data. In essence instead of solving the problem of efficiently storing data by exploiting the native properties of flows, big data systems maximise performance by distributing the data across various systems shards, tables etc. So in essence they do not solve the problem, but just move the problem and gain in performance as the database is no longer a unique entity but several components contribute to the performance each working on a substantial of the data.
At ntop we believe in simplicity, as thus we do not see a solution in creating a complex system that leverages on various servers as the big data paradigm dictates. Instead we believe that studying properties of flows and trying to exploit them for efficiently in both speed and storage space, is the solution. For instance an IPv4 address is a special number with high frequency for local IP addresses, of the protocol is not just a 8 bit value but it’s special as you will see UDP/TCP/ICMP very often and all the other values seldom. For this reason three years ago we have started to design a new flow indexing system able to exploit bitmap indexes, that we call nIndex. However contrary to what you can find in database literature, we do not distinguish between data and index, but the index itself includes the data, so we can save in space simply avoiding to save data but just the index. Having indexes on all columns it allows to have fast queries that are basically limited just by the I/O speed. Thanks to our new indexing system it is possible to deliver performance typical of a big data system, on a single host that can thus be self-contained and do not rely on external systems that might be unreachable in case of network faults (i.e. when the monitoring system is even more important).
Starting with ntop 3.8 we have bundled nIndex with ntopng Pro/Enterprise, so that you can drill down from alerts/activities to flows and packets on a long-term storage system that does not have external dependencies. Currently we consider this technology still in beta (this until we receive enough feedback from our user base) and we want to consolidate it in the the next major ntopng release scheduled for spring.
To use ntopng with the database, run it with option -F "nindex"
sudo ./ntopng -i eno1 -i tcp://127.0.0.1:5557c -F "nindex"
Database flows will appear under the charts, and will reflect the data shown as timeseries.

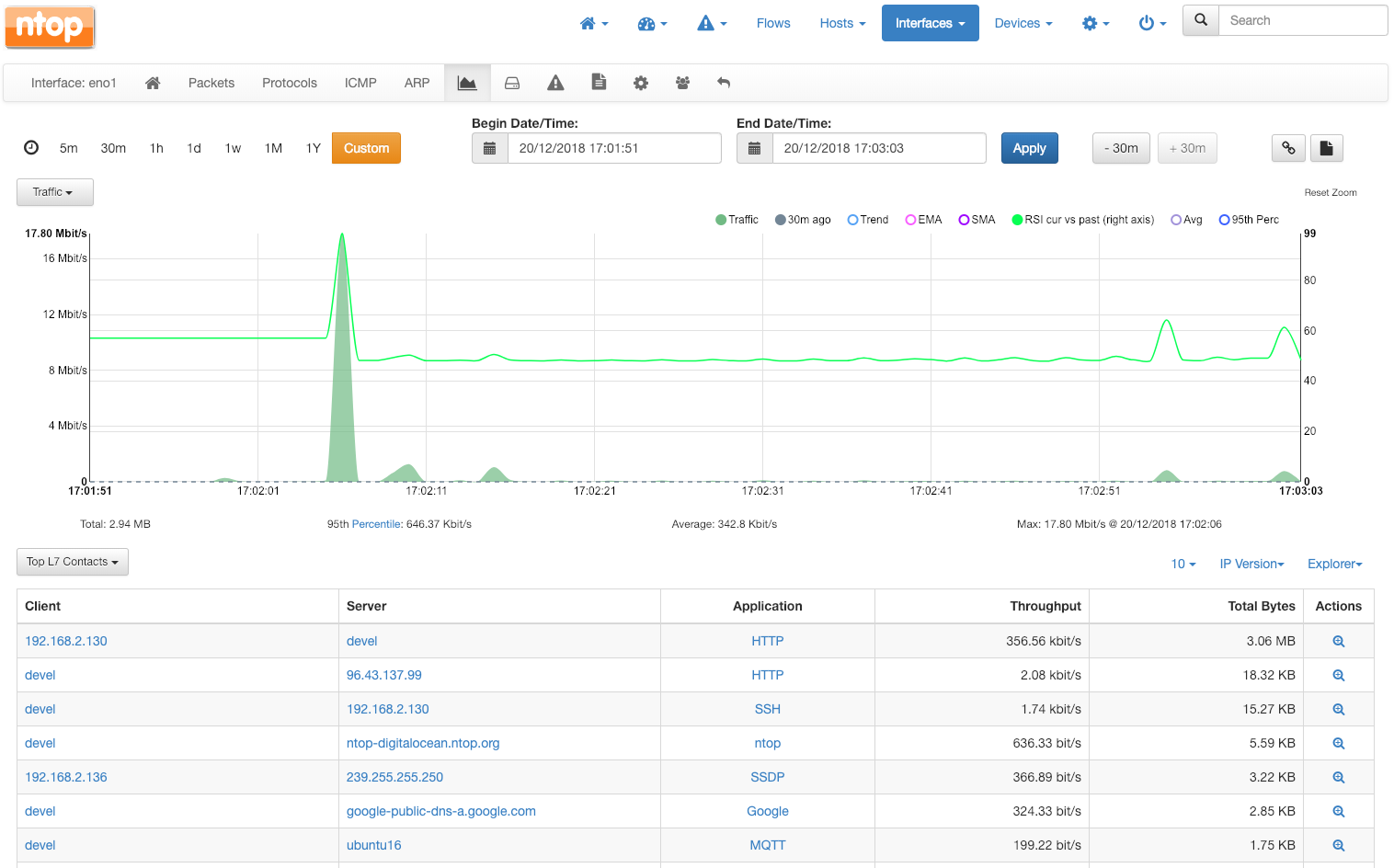
You can drill down to flows clicking on the magnifier lens or download the raw flows by clicking on the black document icons on the top right corner.
We encourage you to try and give us feedback on anything you consider it important for improving it.
Enjoy!