The number of cores per CPU is growing at a rate governed by the Moore’s law. Nowadays even low-end CPUs come with at least 4/8 cores and people want to exploit all of them before buying a new machine. It is not uncommon to see people trying to squeeze on the same machine multiple applications (n2disk, nProbe, Snort, Suricata, etc.) that all need to analyze the same traffic, saving also money for network equipments for traffic mirroring (TAPs, etc.) while reducing complexity.
Both PF_RING ZC and n2disk have been designed to fully exploit the resources provided by multiple cores, using zero-copy packet fanout/distribution across multiple threads/processes/VMs in the former, scattering packet processing on multiple cores in the latter.
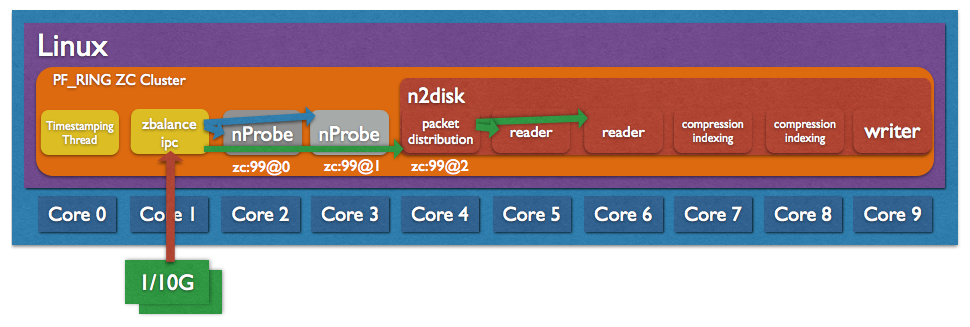
PF_RING ZC comes with a sample application (zbalance_ipc) able to send the same traffic in zero-copy to multiple applications, and at the same time balancing the traffic to multiple instances of each application using an hash function.
For instance, let’s assume we want to send all the traffic to n2disk and distribute it to 2 nprobe instances as in the picture below.

In this case we should run:
Where:
-c 99 is the cluster id (an arbitrary number)
-n 2,1 is the number of instances for each application, 2 nprobe and 1 n2disk
-m 1 is the hashing mode (1 – IP hash) for packet distribution across instances of the same application
-S 0 enables a time-stamping thread on core 0
-g 1 binds the main thread to core 1
After starting zbalance_ipc, we can run 2 nprobe instances using as interface name zc:99@0 and zc:99@1, and n2disk using zc:99@2.
(Please note that using our PF_RING-aware libpcap it is also possible to run legacy pcap-based applications just using the same interface names as above.)
Example:
Where
–dump-directory|-o /storage is the directory where dump files will be saved
–max-file-len|-p 1024 is the max pcap file length (MBytes)
–buffer-len|-b 2048 is the buffer length (MBytes)
–chunk-len|-C 4096 is the size of the chunk written to disk (KBytes)
–reader-cpu-affinity|-c 4 binds the reader thread to core 4
–writer-cpu-affinity|-w 5 binds the writer thread to core 5
As said before, n2disk has been designed to fully exploit multiple cores. The minimum number of internal threads is 2, one for packet capture (reader) and one for disk writing (writer), but it is also possible to further parallelize packet capture and indexing using more threads.
If n2disk is generating an index with –index|-I (or compressing PCAPs with –pcap-compression|-M), it is possible to move compression from the writer thread to ad-hoc threads using –compressor-cpu-affinity|-z <core id list>. It is also possible to move packet indexing from the capture thread to the same threads using –index-on-compressor-threads|-Z.

Example:
Where:
–compressor-cpu-affinity|-z 5,6 enables 2 compression threads binding them to cores 5 and 6
–index-on-compressor-threads|-Z enables indexing on the same threads used for compression (-z)
In order to achieve the best performance with n2disk, it is also possible to parallelize packet capture using multiple reader threads. Using the new ZC-based n2disk (“n2disk10gzc” part of the n2disk package available at http://packages.ntop.org) it is possible to do this also when capturing from a ZC queue (running as a consumer for zbalance_ipc).
In order to do this, the -N parameter is required when running zbalance_ipc:
Where:
Example:
–cluster-ipc-queues 5,6 –cluster-ipc-pool 6 –reader-threads 6,7
Where (all the following parameters are provided by zbalance_ipc):
–cluster-id|-X 99 specifies the ZC cluster id
–cluster-ipc-queues|-W 5,6 specifies the queue IDs to use for internal packet distribution
–cluster-ipc-pool|-B 6 specify the pool ID to use for buffers allocation
–reader-threads|-R 6,7 enables 2 reader threads binding then to cores 6 and 7
Now you know how to exploit all your CPU cores and thus maximise performance. Have fun!